ASC20-21回顾 - 大家都〇等于大家都没〇
ASC20好死不死决赛场地就在妮可,痛失旅游机会。祸不单行,ASC20取消,合并为ASC20-21,公费旅游机会-=2。雪上加霜,疫情还顺手把晚宴给整没了。没有机票,酒店,和大吃大喝的比赛能叫比赛吗!
Day 0
Day0当然是传统艺能——装机的一天。忘了赛前咋规划的了,好像是计划上午要装好机的样子。作为垃圾佬出身的垃圾佬,哦不是,作为垃圾佬出身的运维,装机 应 该 能 分分钟装好,我的装机经验丰富到装烂过一张1080和Xeon Phi(自豪)。结果好家伙,不知道浪潮从哪里捡来这个鬼才设计师,把显卡供电线设计得贼鸡儿短,要大力出奇迹才能把显卡安装在推荐的GPU1和GPU2位置,为了省事我就把显卡装在了GPU1,3位置上了,反正显卡拓扑都差不多,一个NUMA一张卡,理 论 上 没啥问题。
关于装系统的方案,我们从一些人的血的教训以及我自己的血泪史中得出结论,不预装系统到硬盘上。当年我的NAS(垃圾服务器)的硬盘运行在AHCI模式,但HPE的BIOS也是鬼才,读不到AHCI模式下的硬盘的温度(只能读到RAID下的),于是就让风扇狂转。我就把硬盘设置成RAID模式,结果发现硬盘一个区域消失了,报分区表错误,尺寸对不上,最后我不得不把文件拷出来,改模式格式化,再写回去,因此我一直怀疑配RAID阵列有未知的副作用。所以我做了个自动安装的镜像,还整了五个U 盘,这样就能一边装系统,一边装另一台的硬件。
系统装好了,nvidia-smi一看,有一个节点的A100申必消失了。其他队员和浪潮的人老在叭叭说不按推荐的装法是不是会有问题啊,要不要再把显卡的装法改回去啊。我重新插了A100,还是不认卡,吓得我以为刷新了被我害死的硬件的价值的最高记录,7.5w一张的美国金卡还可以买一堆1080了。仔细一看,发现是GPU3位置上的A100认不出,结果挪到GPU2上就认出来了。虽然我坚持认为GPU1,3位装法没问题,暴力装显卡电源线可能伤硬件(更伤手),但还是把显卡装回1,2位了,(不过这次我不去装显卡线了),大概只有浪潮知道为什么GPU3位不能装GPU了。(供电缩水了吗?)
换好显卡位置了,发现有个节点红星闪闪放光芒,亮红灯,进BMC一看,警告有高速PCIe设备运行在低速模式下。拆机重装,感觉安装Riser的手感怪怪的,排查了一阵子,看到一根线的标签卡在Riser的插槽里。好家伙鬼才设计师,标签贴在哪里不好,非得贴在那根线上,还刚好在那个高度上。
期间,为了能通过无线连接集群,不知道谁直接从学校某处掏出了一个长得非常嚣张的硕大的路由器,因此被其他学校认为我们有滥用主场优势的嫌疑,但这玩意虽然看起来很强,可它是TP-Link啊。
折腾了大半天,到差不多四点了,才准备开始跑HPL。为了给其他队上一课,在气势上不能输,功耗的数值必须要大,直接打算跑五机十卡。按下回车,数秒后,功耗下降了。哦,原来是跳闸了。又开机了,压了功耗,又开始跑了,又跳了。虽然作为东道主,我们早就知道跑到7kw会跳闸,但我们应该没跑到这个数啊,过一阵子才意识到,插线板也需要做 负 载 均 衡。给了两路供电,但前五个节点服务器基本全在吸同一路的电,这才蚌埠住了。
跳闸是小事,但不知道为什么BeeGFS好像没见过这种场面,在跳闸之后就很难抢救回来了,折腾了半天,还是没治,放弃治疗了。求稳还是得看NFS,什么BeeGFS,Ceph这种花里胡哨的还是得爬。NFS唯一的毛病就是在存储节点的NFS服务重启的时候,其他的节点一挂载就崩了。我们有另一个运维来管理存储节点,我管理其他的。因为他懒得写好fstab去自动挂载一块xfs盘,每次重启后都要手动mount一下再重启一次NFS服务,在这个期间我只要挂载NFS盘就能触发经典Race condition。这种情况居然连续出现了两次,一崩就重启,重启完就Race condition崩了。最后我按着他的头老老实实把fstab写好了,这样就没必要重启NFS服务了。
插曲:妮可食堂又开始丢人了,这整的什么盒饭啊。THU队上来就问外卖怎么点,SJTU的队员指着饭盒说:你们平时吃的就这?后来才知道这些盒饭是教工食堂整出来的玩意(AP以下的教工还挺惨),由于被吐槽过多,计算中心直接跟食堂说你们别整那些水果饮料了,把饭做好吃点吧。总之这四天成为了我这学期吃得最健康的几天。不知道是不是我在采访里喷饭堂的言论被副校长看到了,他还打了个电话问计算中心大家吃得怎么样。答曰,没出事。
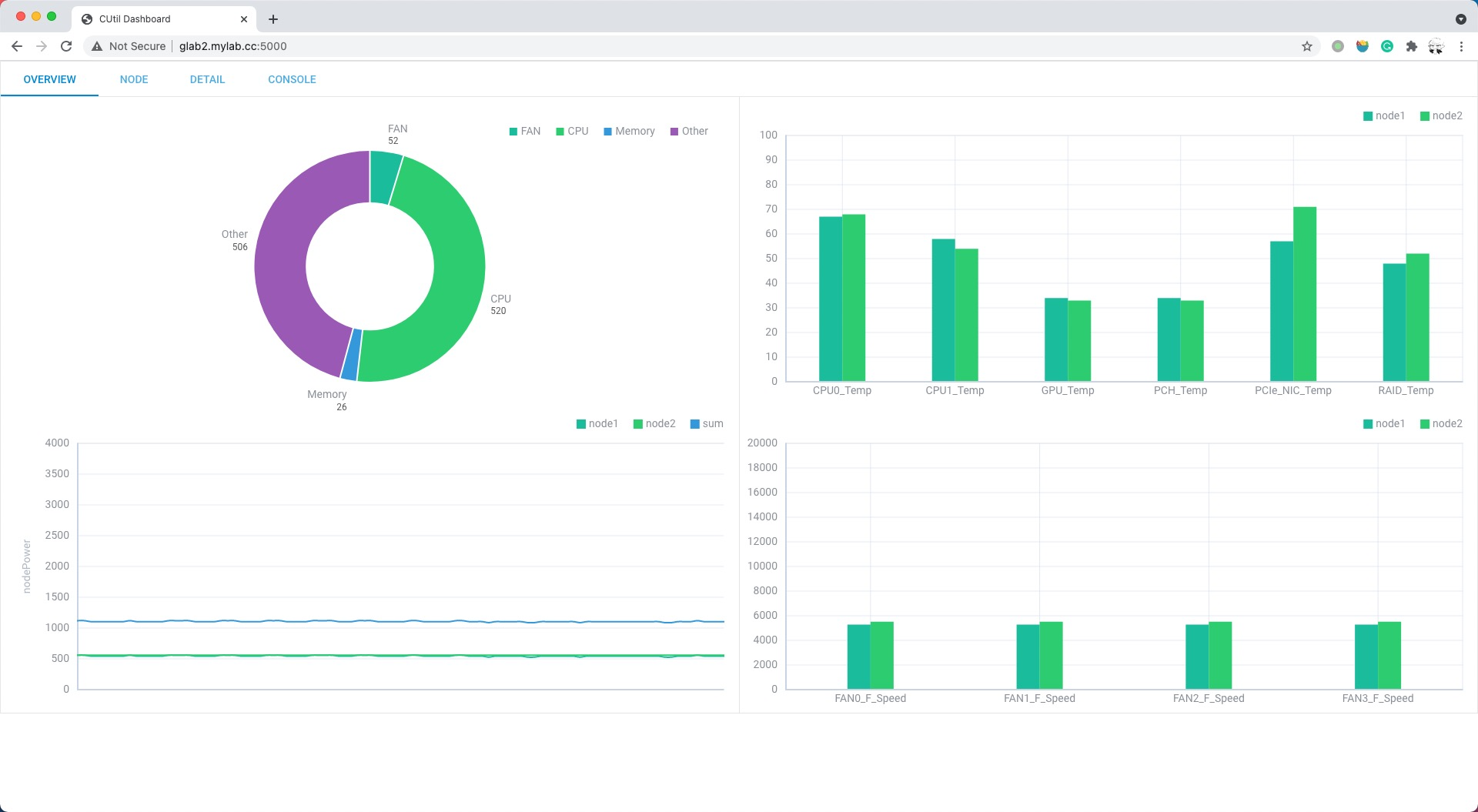
由于嫌弃Grafana太重了,(主要是不会配),晚上在手搓Dashboard,硬是用DHTMLX搓出了一个还看得过去的面板,用Flask和 文 件 系 统 数 据 库 (一个json文件存数据)搓了一个简单的后端,并部署到了一块Jetson Nano上。至于什么网页端的功耗控制,明年再写吧。现场写了几个破烂脚本去手动调功耗和风扇速度,再用clusterssh手动执行。至于自动功耗控制,不存在的。
Day 1
Day 1是最后一天装机配环境的日子了,Day 2以后就是正式比赛,不能重启超功耗了。开机,IP全变了,不知道信息中心搞什么飞机,DHCP租约期还没有某些队员连续不睡觉的时间长,每天还得重配hosts文件。
昨天晚上突然意识到还没检查CPU的C State和P State(再次感谢某人的血泪史),dmesg一看发现intel_idle: does not run on family 6 model,考虑到新硬件的兼容性,我们已经上了Ubuntu 18.04的5.4 HWE内核了,难道这还不够新?cpupower idle-info里果然没有C6 State。一顿搜索找到了Ubuntu 18.04可以用的5.10内核的deb包,于是决定单独拉一个节点过来受害。新内核装好了以后,intel_idle是没问题了,C6也应该有了,但NVIDIA的内核模块没有被重新编译,最关键的是没省多少电,也不知道为什么,保守起见,还是不上新内核了。可能是非CPU消耗的功耗太多了,再从CPU挤挤,省出来了那点功耗估计是非CPU功耗的零头。
待机控制的建议阅读:
关于内存,早就看到有些队给所有机器满上了,可能是上一届ASC让他们得了内存不足PTSD吧。我们还担心内存功耗很大,借了的内存必须在比赛的时候全插上,就先借了32条,能插满两个节点(两节点自带32条),然后测了一下,结果内存的峰值功耗还没有GPU待机功耗大。(最后插满的四节点内存峰值功耗也就100W内吧,工作人员老拿内存功耗说事,还以为功耗有多夸张呢。)于是就决定给四节点满上了,强迫症开心了,没有空着的内存插槽了,但这个时候工作人员又不让借了,说借内存需要确定比赛机器最终配置以后才能把内存拿给你,这种不明说的怕不是刚拍屁股想出来的规则真tm坑。
给节点上好内存的时候,有一个节点又红星闪闪放光芒,BMC说有几根内存条有毛病。把内存全拔了,调换顺序重插一遍。BMC说另外几根内存有毛病,烂掉的内存数量倒是少一点了。我们怀疑是内存金手指氧化了,上一次ASC19我队表演了一手现场擦显卡金手指,还给救活了,所以决定今年表演一手现场擦内存条金手指。擦了一个小时,痛失了半截橡皮擦后,重新插上内存,开机,红灯,BMC的报错和上次一毛一样,还是那几个槽的内存烂了,但是这些槽上的内存已经被调换了,每次内存条都被插到一个随机的位置上,想想这些内存都是新的,应该也不是氧化的问题。我们也懒得这个时候换机器了,等确认机器配置以后再换,正好这个节点也可以当做三带一方案里的那个load resistance,负责耗电就行,不影响我们测三机六卡。
最后测出来三机六卡和四机八卡同功耗限制下跑HPL的成绩差不太多,但四机八卡的HPCG的成绩远好于三机六卡,毕竟众所周知HPL吃浮点计算能力,HPCG吃总内存带宽,内存读写功耗又远低于浮点计算功耗。
五点左右的时候确定了最终配置,满内存四机八卡,其他队的方案估计也差不多。今年的机子属实大火炉,待机400W满载1kW+,单节点还只能上两GPU(把有线网卡废了理论上能上三GPU),所以应该整不出太多花活,白准备了十多张美国金卡了。六点的时候按最终方案配置好了,还剩下了一点时间测测HPL和我的QuEST。晚上因为之前两天每天只睡四个小时,就决定啥也不干了,直接躺床去世。
Day 2
早上不想起床,感觉没自己什么事(其实跑HPL的那个人指望我去压功耗),就决定来一手可控迟到,多睡了半个小时(其实已经睡了差不多九个小时了)。在路上想着我是不是最后一个到场的,结果并不是,甚至还是前几个到场了的。大家都迟到了等于我没迟到
八点开始的比赛,十一点就要交HPL的成绩,九点才开始调HPL。第一次跑,就跑出了一个比预期好的成绩,第二次跑更好了。我说要不就交了吧,刚启动的机器比较凉,但跑HPL的那个人是个赌狗,后来机器不负众望,一次跑得比一次烂,甚至还出现了超功耗的情况。后来实在顶不住了,他说最后再跑一次,我把机子多冷却了一会,结果,自然是,跑出了一个史低。最后一次是不可能最后一次的,那肯定是又说着最后再跑一次又准备跑一次,我看不下去了,就去吃了个茶歇,想着我走开,没人去控制风扇和功耗,他就不能立刻跑HPL,机子就可以多冷却一会,结果远远地看到那个人敲着我的电脑自己开始跑HPL,拖住他的计划大失败,我还是得跑回去接手功耗控制,毕竟没有写读HPL的log来调功耗的脚本,全靠手动实现多阶段的功耗控制。emmm,最后,呃,跑出了个史高,太草了,赌狗的大胜利。至于HPCG,我们最初就计划跑一次HPCG,跑出结果就完事了。
大概十点交了HPL成绩,拿到了当天其他的赛题。PRESTO给了几十个GB的输入数据,突然我就慌了啊,不是说没有吃IO的应用吗,我们共享存储可是NFS over 1Gbps Ethernet,光是分发这些数据都难顶。这个时候想到了三个解决方案,用MPI分发数据到本地SSD上,让PRESTO从本地SSD读取数据;配置IP over IB,然后用scp分发数据到本地SSD上,或者NFS over IP over IB;配置NFS over RDMA。第一个方案,懒得写MPI程序。第二个方案,因为残留的BeeGFS可能阻止IB服务的重启,可能会炸。第三个方案,可能可行。找了两个在别的地方的节点,试着配了一下,载入NFS over RDMA内核模块没问题,但是mount的时候就失败了,在dmesg里看到这个内核模块已经爆炸了,所以第三个方案也不行。这个时候让PRESTO试着跑起来了,读取共享存储的数据,但dstat发现以太网卡其实没啥流量,也就是说根本没必要管共享存储的IO问题。
之后还出了一个事故,跑HPL那个人为了测MPI是不是正常的,又跑了一次HPL,结果把之前准备用来提交的HPL输出数据给覆盖了,好在最后不影响成绩。
PRESTO那边折腾了半天魔改的多机版,又是折腾出了纯MPI的,发现还没有单节点来得快,结果拖到了很晚才开始正式跑PRESTO。惊为天人的是,大家一顿操作猛如虎,还是成功的在最后几十分钟把所有的算例跑完了。
不过跑是跑下来了,提交文件的时候又出问题了,输出文件太大了。我们先后经历了U盘存不下,拷得慢等问题,最后换成了某位热心的工作人员提供的移动SSD硬盘,但还是慢。最令人窒息的事情是卡在了umount命令上,iostat看到一直有数据写入移动硬盘,又刚好听到了国防科大硬拔U盘造成了数据损坏,不得不重新复制的悲报,所以大家也没敢硬拔,只好躺在地上无所事事。直到七点半,实在是等不下去了,因为国防科大队已经重新复制完文件溜了。所以只能硬拔,格式化,重新复制。这一次用了rsync,而不是用的cp,复制速度终于符合SSD的表现了,腰不疼了,腿不酸了,umount也有劲了。
晚上大家都没吃(除了我),老师就让我们用破解版饭卡去西餐厅吃,今天加班不亏。
Day 3
其实我Day 2的主要工作基本上就是压功耗,也就是说没啥事,Day 3就有我的QuEST了,所以这一天没怎么迟到。拿到算例一看,好家伙最少模拟34位量子比特,显存直接爆炸了。刚好八卡共320G的显存也就够模拟一个33位的量子比特,出题人一定是故意的。算例四的量子比特位倒是挺少,20多位,但是模拟了一堆量子比特,内存占用算下来等效于模拟一个35~36位的量子比特。最后决定还是跑CPU版的,自己魔改出来的分布式多GPU版本根本用不上。
一开始决定给AI题先跑,因为之前的情报显示我可能需要现场改QuEST多GPU的代码,因为决赛会提供一个加了料的QuEST的源代码,加了几个门。Day 3前一天晚上AI组的同学自信得一批,说绝对稳如老狗,因为原先题目说在BERT模型上搞,他们就对着BERT做了一堆优化,效果好像还不错。结果Day 3早上,组委会给了个ALBERT,好家伙,名字里倒确实有BERT这四个字,他们做的优化不仅是 白 搞 了,他们现在还得去改代码把优化手段删掉,然后发现了loss根本不收敛。不过他们业务能力极强,用了一个小时把bug修了。折腾到大概十二点开始训练模型,决赛最多允许训练到三个Epoch,一个Epoch大概需要训练半个小时,训练前两个Epoch屁事没有,最后一个Epoch还差一分钟训练完的时候居然超功耗了,没办法,还是得把程序鲨了。其实可以用在训练中保存的checkpoint来推理,但是因为不是正常退出,有一个关键的用来判定训练时间的log没有打出来,所以之前的结果还是白给了,虽然有人提出可以 人 脑 生 成 一个log,但估计不太合规,还是算了。此时已经一点半了,不跑别的就来不及了。
在AI训练的时候,我在现场对他们提供的加料版QuEST的源代码做CPU优化。一年前的时候我们就发现MPI和OMP混合比纯MPI快不少,但是用mpirun启动混合模式的程序就非常痛苦,特别是Intel MPI。OpenMPI好歹给了map-by和bind-to选项,Intel MPI调了半天genv的变量都没有让MPI给OMP留出指定数量的核心,而且Intel的-print-rank-map的输出非常抽象,因为就没输出什么有用的信息。所以计划用slurm辅助Intel MPI启动混合模式的程序,结果这个时候有一个节点的slurm崩掉了(那个节点曾因为忘记开风扇过热关过机),什么slurmd -c都不好使,所以又花了一些时间去抢救slurm,过了几十分钟,不知道为什么slurm又活过来了。准备开始跑QuEST的第一个算例量子傅里叶变换了,按下mpirun,过了几秒就崩了,报ulimit太小,但是我魔改的系统已经把ulimit开到unlimited了。好家伙,最后发现解决方案居然是换root用户跑,大概二十分钟就跑出结果了。
然后是第二个算例,这个算例是量子傅里叶正逆变换,而且它的量子比特位数比第一个大了1位,所以估计需要四倍于第一个算例的时间,但跑了一个小时程序还没有结束,感觉不太对劲了。我们开始讨论要不要结束程序,考虑到沉没成本过高,我坚持让程序跑完。过了一阵子,去检查了一下log,发现在计算开始半小时左右slurm报告它kill掉了什么东西,看了一眼htop,程序似乎还在“正常”跑,所以我以为slurm没kill成功。程序跑了一小时二十分的时候,感觉太不对劲了,又开始讨论要不要结束程序,这个时候我还是不太想杀死它,打算让AI训练和QuEST一起跑。又过了一阵子,仔细检查htop,这才发现QuEST每个节点都只剩下了三个rank,有一个rank与世长辞了,应该是被slurm害死的那个进程,QuEST再见了您内。
至于QuEST的第三个算例,这玩意光是编译就挺麻烦的。虽然组委会给了Makefile,但是QuEST已经迁移到了CMake了,那个Makefile只能编译出一堆错误。而且这个算例和其他不一样,其他算例基本上是一个cpp文件,这个算例是几个cpp文件和一个py内鬼,这个内鬼不仅让编译变得困难(依赖Python的头文件),估计还能起到拖慢程序的重大作用。不过我们第二个算例都跑不下来,就没第三个算例什么事了。
这个时候距离比赛结束还有大概1个小时,神秘应用能编译,但只能跑单线程,估计跑不完一个算例。所以大家稍加思索,最后决定保AI。AI那边本来应该没有什么大问题,至少跑完一个Epoch是没问题的。但不知道为什么,跑到三四百秒的时候进程被杀死了。又跑了一次,又被杀死了,原因不明,只见屏幕上有个Ctrl-C,但其他人都声称没有误触或者结束进程,难道是slurm杀疯了?也不太可能啊。但不管怎么说,我们的时辰快到了。好在AI组改代码去捕获Keyboard Interrupt,然后保存模型,把log打出来。原本的目的是为了让训练能跑多久跑多久,跑不完就Ctrl-C,结果让那个训练了400秒的模型成功保存下来。测试发现那玩意的准确率还有78%,训练三个Epoch也才85%。虽然准确率丢了点分,但时间分拿满了啊。Anyway,反正没别的东西交了,最后就把这个400秒的模型交上去了。
Day 4
又是早起的一天,答辩无事发生,发挥比赛场上好多了,不愧是南方pre大学。下午领奖,就记住了宣传片里我队恶臭的口号,还有妮可坟头的招生广告。rank第五,别的奖项一个都没捞到,看在全队成员都是第一次打线下的现场赛的份上,这成绩还说得过去。赛前还吹牛批说要拿广东第一,最后倒是喜提广东倒数第一,深圳第一倒是保住了,因为也不存在深圳第二。不过Day 3崩成这样还能排第五,看起来大家都崩了,大家都崩等于大家都没崩!
后来吹水的时候听到了有人用了多GPU版的QuEST跑了几个算例,想了想确实很容易就可以写出来一部分Rank的StateVector放在显存上,一部分Rank的放在内存上的程序,这样显存爆了的情况下还可以让GPU和CPU一起算。之前没参加过ASC的现场赛,还是太年轻,我居然会去期待组委会是一群好人。组委会的恶趣味还包括年年都搞气象模型这种恶心东西,神秘应用可以读写PB级别的数据,还好没梭哈神秘应用,不然我们那个玩具级NFS必然顶不住。我最气愤的其实是组委会把晚宴取消了,晚上又得去吃学校里的茶餐厅了,每次比完超算比赛就去茶餐厅也太难顶了,西餐厅人均100的餐标也就能吃个夜宵。